# 文章评论功能前后端实现方案总结
作者:南侠 (opens new window),编程导航星球 (opens new window) 编号 29240
本文主要就前后端嵌套评论功能的实现方案进行总结和讨论。主要包括前端显示的两种方式、后端评论数据的两种存储方式。
效果图: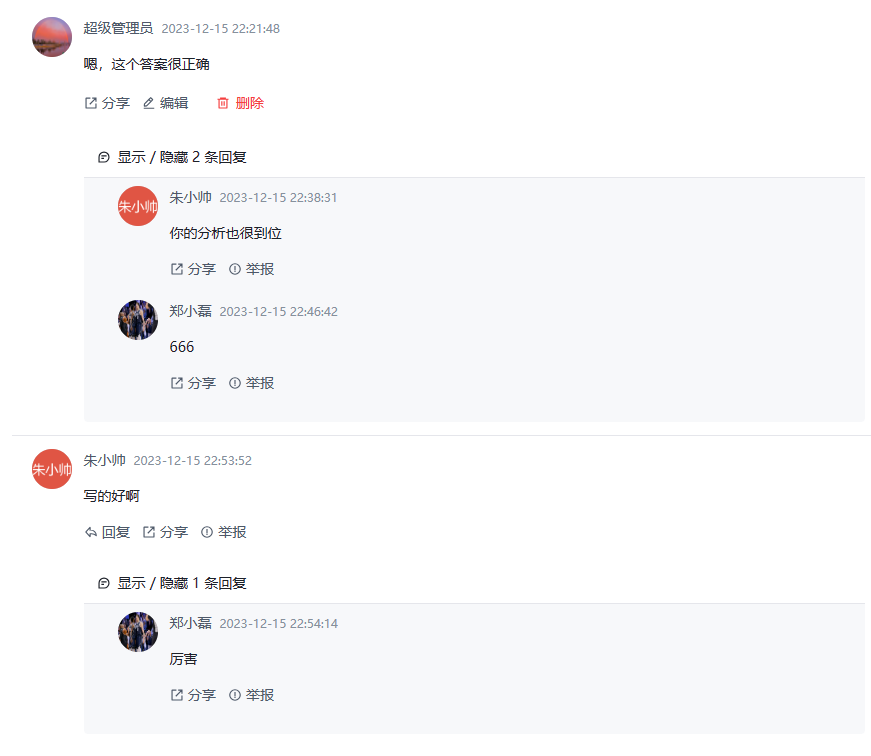
# (1)前端
# 1. 两种方案
不同角色看到评论类别的操作是由不同的,比如,本人发布的评论我们可以对其进行编辑和修改,且逻辑上不能举报自己,所以在同一页面实现不同显示,我们就需要状态量去控制不同页面元素的显隐。
在此,有两种方案:
- 由前端设置状态量,并通过后端的数据特征维护这些状态量,判断结束后,前端就能实现不同情况的合理显示。这种方案就是后端省事,前端需要自己做相当一部分事情去判断,要麻烦一些。
- 数据驱动,传入嵌套评论结构,给页面渲染。即后端在返回前端评论信息时,将这些状态量一并返回。这种的好处就是前后端都相对方便,前端专注于状态量判断和显示,后端专注于状态量的维护,在后端维护是方便的,因为数据就是从此返回的。
# 2. 方案对比和总结
这两种方案各有优劣,取决于具体的项目需求、团队分工、性能考虑以及维护成本等因素。以下是对比这两种方案的一些考虑因素:
# 方案一:前端设置状态量,后端维护数据特征
# 优势:
- 前后端职责分明: 前端负责逻辑判断和显示,后端专注于数据维护。
- 前端自由度高: 前端可以更灵活地处理和呈现不同状态,定制化程度较高。
- 性能优化: 前端可以根据需要灵活控制页面的显示逻辑,减轻后端负担。
# 不足:
- 前端逻辑复杂: 前端需要处理复杂的状态判断和页面显示逻辑,可能增加前端开发难度。
- 可能涉及重复逻辑: 如果有多个地方需要类似的状态控制,可能需要在多个地方重复实现相同的逻辑。
# 方案二:数据驱动,后端返回状态量
# 优势:
- 简化前端逻辑: 前端只需要根据后端返回的状态量进行简单的判断,减轻前端的逻辑复杂度。
- 统一数据源: 所有状态相关的信息都来自后端,可以避免状态不一致的问题。
- 后端灵活性: 后端可以更方便地修改状态相关的逻辑,不需要修改前端代码。
# 不足:
- 前后端关联紧密: 前端和后端的逻辑高度耦合,可能导致前后端开发难度增加,后端需考虑更多的前端逻辑。
- 性能考虑: 需要传输更多的数据到前端,可能增加网络传输成本。
# 综合考虑:
- 项目需求: 如果项目对前端交互有较高的定制需求,方案一可能更适合。
- 团队技术栈和分工: 如果团队前端技术水平高,能够轻松处理复杂逻辑,方案一可能更适合;如果后端能够方便地维护状态逻辑,方案二可能更适合。
- 性能需求: 如果对网络传输和前端性能有较高要求,方案一可能更合适。
在实际应用中,也可以综合两种方案,根据具体场景采取不同的策略,例如,简单的状态量由后端返回,复杂的逻辑由前端处理。
# (2)后端
评论功能的关键点我认为是在于如何对评论的嵌套和父子关系进行合理的数据存储。对于文章评论功能,可做出以下结构划分。
- 文章-一级评论(父级评论):即用户对于文章做出的评论;
- 一级评论-二级评论(父-子评论):即其他用户对文章评论的评论,以及父级评论者对这些评论的回复,简而言之,就是评论者之间的交互,其实这里已经与文章没有关系了,因为交互的对象都是评论者了。
基于1、2,本文提出了两种存储方案予以处理。
# 1. 简单方案
除文章表之外,只设计一张评论表:article_comment。
字段包括:
- articleId:文章id
- senderId:发送者id
- receiverId:接收者id
- comment:评论内容
具体实现如下:
- receiveId为空时,表示该条评论是针对文章的,反之是针对评论者的。
- 限制:同一个人只能对一篇文章做最多一条评论,才能确保这个三元组(articleId-senderId-receiverId)的唯一性,即他人对一个人的评论做出的评论才能保证唯一,且这种方案下,被评论者也无法对评论者进行回复。局限性还是蛮多的。且没实现两级评论的解耦(文章-评论;评论-评论)。
- 不过,如果能容忍以上限制,那么我们可以很简单的实现一个简单的评论功能。
# 2. 完备方案
第二种方案则能完备的突破简单方案中的限制,实现完整的功能。
即,除文章表之外,设计两张表:
- article_comment
- articleId:文章id
- userId:评论者id
- callId:流水号,作为该条记录的唯一标识
- comment:评论内容
- comment_relation
- userId:评论者id
- comment:评论内容
- self_callId:该条记录的流水号,唯一标识
- target_callId:评论的那条记录的流水号,来源有两个:1. article_comment表中的callId(父级评论的流水号);2. comment_relation表中其他记录的sefl_callId流水号.
通过这两张表,我们就能实现,多级的评论和回复。
- 为什么用流水号而不用id:因为target_callId的来源有两个表,用记录id有可能会重复造成冲突。
- callId流水号是该方案的核心,必须保证其唯一性。
- 这种方案的好处是我们无需关注评论者的信息如何如何,只需将流水号作为唯一标识即可,父级关系就用target和self区分即可。同时这种方案,实现了解耦,现在我们是文章评论,那么如果我们换成歌曲的评论,我们只需改article_comment,而comment_relation是可以复用的,实现了评论与被评论之物的解耦。
# 3. 方案总结和对比
当对比两种方案的好处时,我们可以着重考虑它们在可维护性、灵活性、性能以及扩展性方面的差异:
# 简单方案的好处:
- 易实现和维护: 数据表结构相对简单,易于实现和维护,前端和后端的开发相对较为轻松。
- 适用于简单场景: 对于不需要多级评论和回复的简单场景,这种方案足够满足需求,减少了系统的复杂性。
- 性能优化: 由于数据表结构简单,可能对数据库的查询和操作有一定的性能优势。
# 完备方案的好处:
- 多级评论和回复的支持: 这是该方案的核心优势,可以实现更丰富的评论交互,提高用户体验。
- 解耦性强: 通过两张表的设计,实现了评论与被评论之物的解耦。对于不同的被评论对象(例如文章、歌曲等),只需修改一张表而另一张表可以复用。
- 灵活扩展: 由于流水号的设计,方便扩展和修改评论系统的其他功能,如点赞、举报等。
- 更高的定制化: 具备更高的定制化程度,适用于复杂的业务场景,满足更多需求。
- 可复用性: 评论关系表(comment_relation)的设计使得该方案更容易在不同模块中复用,例如可以用于其他社交互动。
# 综合对比:
- 简单方案适用于: 简单的评论系统,不需要多级回复的情况,且对数据库设计和维护要求较低。
- 完备方案适用于: 复杂的评论系统,需要支持多级评论和回复,并且对系统的扩展性、定制化程度有较高要求。
总体来说,选择哪种方案应该根据具体的业务需求、系统规模和团队技术水平来决定。在简单场景下,可以选择简单方案,而在对评论系统有更多要求的情况下,完备方案可能更为合适。